Some of you may remember that XX Network mainnet was originally scheduled to start this week, but was pushed to next week.
That turned out to be helpful as I was able to complete some architecting, planning and testing related to mainnet, and I’m almost ready for mainnet.
Implemented ¶
My current status as of today (November 10, 2021):
- Analysis of performance, application resource requirements, database requirements (including backup & restore) completed this week
- XX Chain, Node, and Gateway all ready to run in the cloud (all OS, apps & configuration files in place)
- XX Node is running in the cloud
- XX Gateway is still running on-premises
I’ve just finished migrating the Node and I may still move Gateway to the cloud before mainnet.
To be implemented before mainnet ¶
- Implement advanced performance monitoring (improve on the current approach that I have on-premises)
- Document all settings
- Set up remote backup for two Postgres databases (already tested with the larger (Gateway) DB, and one-off attempt with the smaller (Node) database worked fine)
- Set up backup for XX chain (already tested)
To be implemented by early December 2021 ¶
- Centralize log collection (improve on the current approach that I have on-premises)
- Write custom service-checking scripts and set up application-aware monitoring
- Implement canarynet on-prem and use it to conduct failover and failback testing between on-prem and the cloud
Summary ¶
It took me around three hours to move Node service from on-premises to the cloud. This includes some unexpected problems (firewall, etc.).
The first big drop (protonet era 741) happened on switch-over. After that one era was missed (spent in waiting).
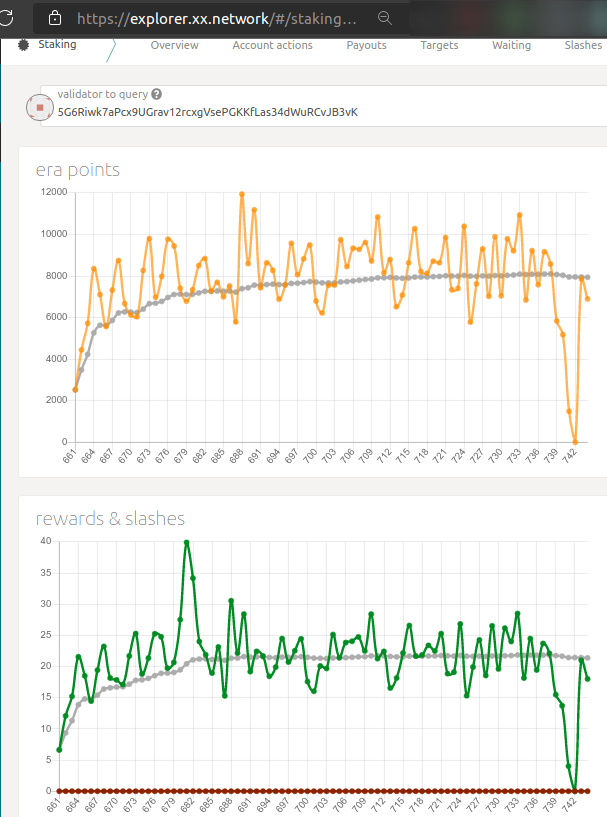
Node after the move:
What does that mean for folks who nominate us?
- Backup and restore of both the settings and data (XX chain, Postgres
cmix_nodedatabase) was successful - Permissioning-related steps were handled without problems
- Failback to on-premises should work the same way, only in the opposite direction
Once I complete all of the steps outlined above I believe I should be able to recover from most unplanned site failures within 12 hours, and move nodes around within only two-three hours.