- MainNet
- Monthly update for March 2023
- Monthly update for February 2023
- Monthly update for January 2023
- Monthly update for December 2022
- Monthly update for November 2022
- Monthly update for October 2022
- Monthly update for September 2022
- Monthly update for August 2022
- Monthly update for July 2022
- Monthly update for June 2022
- Monthly update for May 2022
- Monthly update for April 2022
- Monthly update for March 2022
- Monthly update for February 2022
- Monthly update for January 2022
- Monthly update for December 2021
- Day 33 (Dec 22, 2021)
- Day 12 (Nov 30, 2021)
- Day 11 (Nov 29, 2021)
- Day 1 (Nov 18, 2021)
- Day 0 v2 (Nov 17, 2021)
- Day 0 v1 (Nov 16, 2021)
- ProtoNet
MainNet ¶
Monthly update for March 2023 ¶
No downtime or any issues except for the usual Internet slowdowns which degrade performance on certain days.
Maximum commission for Team Multiplier-backed nodes has been increased to 22%. I haven’t adjusted commission yet, so as of April 8, 2023, PRIDE is still at 17.9%.
There’s a community run “rewards payout” script that pays out rewards automatically - at least for time being, as certain donors have chipped in - so payouts for UNITED-VALIDATORS have been very regular.
Monthly update for February 2023 ¶
More than one week of poor network performance across the board. Really annoying, but it’s completely outside of my control.
There was no downtime due to maintenance or other issues.
Monthly update for January 2023 ¶
There were days of poor network performance.
There was no downtime due to maintenance or other issues.
Monthly update for December 2022 ¶
Nothing unusual to report: as usual, there were 1-2 days of poor network performance after which I cut commission for 2 eras.
xx gateway code was updated to add TLS encryption and I happened to be reasonably alert to that schedule so I prevented significant downtime due to failed gateway update pushed out.
Other than that, the quality of nodes on xx network has improved as the changes to Team Multiplier calculation created better economic incentives, so recent months haven’t been nearly as frustrating as before.
Monthly update for November 2022 ¶
Having moved PRIDE to the cloud, I used the opportunity to complete some overdue to-do’s from my monitoring wish-list.
I still don’t use any alerts, but now I monitor services across all nodes and not just TCP/IP ports, but actual services.
After this month’s gateway code updates all three nodes haven’t had issues so I haven’t felt the pressing need to do something about alerts.
The benefit of new monitoring is I no longer need to login to every machine or check the status in the XX Dashboard or Wallet - I just watch one page which has everything I need and nothing more than that. To that last point - I built the monitoring partially by writing own monitor scripts which use very little resources (less than 20 MB).
I’m updating November notes in advance (on November 26), but everything has been stable and smooth this month.
Regarding ENVY and SLOTH, the big news is I closed them to nominators. As before nominators smaller than 20K were left on board although I don’t need their nominations (I’ve more than 20K in extra nominations on each node).
Monthly update for October 2022 ¶
I had a big problem with UNITED-VALIDATORS/PRIDE in October: first it suffered hours of unplanned downtime due to a terrestrial cable cut caused by construction crews (era 331). Hours later they fixed it and it seemed like everything was fine. But it wasn’t.
Two weeks later they arraynged scheduled downtime to fully fix the problem and after that PRIDE’s performance went down big time.
I don’t know the details, but my theory is the first cut made them reroute traffic to a spare line potentially reserved for commercial customers, resulting in no impact except for the downtime. But after they fixed the original line, it wasn’t done properly and it made the connection useless for running a node. And few days later PRIDE dropped out of validator set.
So with more than one year left on my high-speed subscription plan, I had to either move the node or give up on running it. I moved it to the cloud in era 362 so now ENVY, SLOTH and PRIDE are all running in the cloud.
Monthly update for September 2022 ¶
There haven’t been noteworthy events this month.
- UNITED-VALIDATORS/PRIDE - nothing out of ordinary
- UNITED-VALIDATORS/ENVY and UNITED-VALIDATORS/SLOTH - nothing out of ordinary
It’s hard to tell why September was trouble-free. If I had to pick a reason I’d say it’s because some of the recent Ubuntu updates made systems perform well, and I haven’t had big network problems either.
It should also be pointed out that the increased competition that appeared thanks to the changes in TM rules that I advocated for have benefited the network - it runs better and processes more MTPS.
I voted against validator slot expansion because it’s not necessary at this time.
Monthly update for August 2022 ¶
There haven’t been noteworthy events this month.
- UNITED-VALIDATORS/PRIDE - network performance has been stable this month and the node has performed within expectations
- UNITED-VALIDATORS/ENVY and UNITED-VALIDATORS/SLOTH - these have been impacted by a period of high international network latency, and I’ve had some minor external technical troubles which didn’t take too long to spot so they didn’t drop out of validator set. Their gateway VMs have been upgraded to avoid database timeouts and since then there have been no issues.
Monthly update for July 2022 ¶
Having spent almost one month running XXV4 (“ENVY”) and XXV5 (“SLOTH”) out of Germany due to geo-mulitplier reset, I moved the nodes back during third week of July because the new geo-multiplier took effect this week.
I’ve experienced several PostgreSQL database timeouts on gateways, but I they didn’t last long enough to make the node drop out of validator set. Unlike in June, I did not lower my commission after those events because downtime was not caused by me.
- UNITED-VALIDATORS/PRIDE - unstable, but decent performance at around 85% of best node
- UNITED-VALIDATORS/ENVY and UNITED-VALIDATORS/SLOTH - usually 85-90% of top performing node in the era
Monthly update for June 2022 ¶
The referendum for geo-multiplier reset unexpectedly passed, and all regions were set to geo-multiplier 1.00.
This made me move my TM backed node (PRIDE aka XXV3) to less expensive hardware, as the drop in xx earnings may not be sufficient to cover higher expenses (we’ll find out when xx coin becomes tradeable). Meanwhile I deployed two new nodes in West Europe (ENVY and SLOTH) so now I have three nodes.
Geo-mutliplier may return in July, after which node locations and configurations will be evaluated and possibly changed.
Monthly update for May 2022 ¶
I experimented with XXV3 (my TM-backed node) to maximize its performance, and try to figure out if the additional spending can be justified. The problem is, we still don’t know the price of xx coin, so I still have no answer to this.
Monthly update for April 2022 ¶
Issues with Team Multiplier and Phragmen made me take the second, independent node (XXV2) offline and use the wallet for nominating. Such are effects of TM socialism (Atlas Shrugged, etc.)
Monthly update for March 2022 ¶
The entire network is heavily impacted by the poor performance of nodes in Ukraine and Russia.
I’ve had XXV2 Gateway die once - probably due to too many network errors - but I spotted it early enough.
XXV2 dropped out of active validator pool twice during the month of March:
- Once before I’ve started nominating it, when a large nominator left and the validator and remaining nominators’ wallets didn’t have enough funds to get the node re-elected
- Once after I’ve started nominating it, when Phragmen put 0 xx on it, exposing it to the same problem and leaving it unelected…
Now I nominate both XXV3 and XXV2 and so far that’s been enough. XXV3 also has a Team Multiplier, so Phragmen usually allocates most of my own coins to XXV2.
My plan for April is to wait for xx coin launch and potentially stand up another node.
Monthly update for February 2022 ¶
The first half of February hasn’t been great. I’m especially unhappy about the poor performance of XXV2.
If you look at the performance chart above or in Explorer, it’s easy to see that day-to-day variations are very large. Hardware resources are practically reserved, so it’s easy to tell it’s either the network or the peers in combination with unlucky grouping.
The second half was better, even though I didn’t make any changes. This shows that factors impacting the nodes’ performance are indeed external.
I haven’t done much infrastructure-wise, besides some “internal” work. One reason for this is that I was busy, and the second is I’m waiting to see how forthcoming changes impact the network (as a reminder, we’re awaiting two big changes: one is change in geo-multipliers and another is the ability of Team-backed validators to stake both own and other nodes).
My plan for March is to move XXV2 to another hosting provider and then resume work on infrastructure improvements, but I will make that decision after above-mentioned changes.
Monthly update for January 2022 ¶
Highlights:
- Launched my second node, XXV2, and thanks to good management (timing, commission rates, uptime) managed to keep it online despite its very low stake (only 16K xx)
- Delivered on my promise regarding predictable commission schedule
- Continued infrastructure improvements
- Monitoring already in place helped me avoid unplanned downtime on at least two occasions in January
Infrastructure:
- Added advanced centralized logging which works but needs further enhancements to become useful
- Improved existing monitoring scripts
- Validated correct functioning of gateway database backup (DB restore test is still a TODO item)
Uptime and performance:
- XXV commission lowered to 5%, XXV2 commission increased to 3% to narrow the spread and make each node’s commission in line with going rates but still competitive
- Even without changes on the systems in January, their performance isn’t very consistent which reflects the dominance of network quality and peers and can be observed (dips in the nodes’ points)
- XXV2 isn’t very profitable because it’s got over 450K in nominations which tells me there is demand for another node with similar value proposition
- XXV2 Gateway failed to restart causing a few hours of downtime after a centrally orchestrated Gateway update in late January
Monthly update for December 2021 ¶
Highlights:
- After 30 eras and plenty of trial-and-error, I now believe my first (and at this time, only) node “XXV” is stable and various configuration settings and options are close to optimal
- I wouldn’t say all “strange” issues happened due to external factors, but I’m sure some did (more on that below)
- Due to repatriation (geo-multiplier for my region is highest, I just haven’t been taking advantage of it) and small configuration improvements, current week has been best so far in terms of cMix rounds processed. I care about predictable performance and I wasn’t 100% happy with it in the cloud

- Related to that predictability objective: I repatriated the node from the cloud because of the persistent performance drop in eras 21-32 and a cMix/network problem, neither of which I couldn’t explain or do anything about. I guess the performance drop was caused by a noisy neighbor on the same cloud host, but I couldn’t fix it even as I increased hardware resources (all I got was one-off spike in era 27, maybe due to xx chain lottery effect)
- Other objectives - about 20% done
Let’s look at one of those mystery cMix (or network?) events, this time in era 40 earlier this week.
Spike in cMix precomp failures (Dec 26-27, 2021) ¶
Late last week and early this week I had another 24 hour period of strange failure spikes.
It started on its own in last hours of last week (Dec 20) and also affected the first day of this week (Dec 27).
Why do I think it wasn’t me?
- I didn’t change any setting, updated or restarted services or OS because last week I repatriated the node and it was running very well (52,000 points per day or better - see the chart above)
- Node went from 1.30% to 1.87% precomp failure rate for the week in last 12 hours of Dec 26, and to over 5% (weekly average on Day 1) this week
- More than 50% of the rounds that failed during that period involved 5 or so other nodes (all ANZ nodes, which was surprising given the relatively short distance, and 2-3 from North America and Western Europe). cMix round failures involving those nodes were extremely quick (not even timeouts, but simply instant failures to connect during precomp phase). This was similar to other unexplained incidents I saw while in the cloud, but less severe
- After close to 24 hours of issues, I made some changes to network tuning parameters as the node was already unstable. I think the problem resolved itself and so far (Dec 31) precomp failures (average) decreased to 1.96% for the week
Next time something similar happens I’ll just let it be and watch it for 48 hours to see if it fixes itself on its own.
Performance analysis ¶
XX chain is a lottery, so I just look at weekly cMix stats from MainNet dashboard: successful cMix rounds, and precomp and realtime failures and averages.
- PC/RT TO - PreComp and RealTime timeouts
- PC/RT % - % failed
- PC/RT s - seconds taken
- cld, rsd - cloud and residential
- cMix - cMix or networking-related issues without known root cause
| Week | cMix Rounds | PC TO | RT TO | PC % | RT % | PC s | RT s | Comment |
|---|---|---|---|---|---|---|---|---|
| 2021/11/15 | 15870 | 490 | 188 | 1.85 | 1.15 | 11.34 | 2.54 | Partial week 1 (cld) |
| 2021/11/22 | 24179 | 673 | 69 | 2.43 | 0.28 | 11.84 | 2.64 | Self-inflicted interruption (cld) |
| 2021/11/29 | 19843 | 413 | 48 | 0.24 | 1.80 | 11.02 | 2.74 | cMix (cld) |
| 2021/12/06 | 24951 | 440 | 63 | 0.25 | 1.48 | 10.96 | 2.76 | Stable (cld) |
| 2021/12/13 | 24914 | 431 | 77 | 0.30 | 1.40 | 11.01 | 2.73 | Stable (cld) |
| 2021/12/20 | 25661 | 548 | 67 | 0.26 | 1.87 | 10.48 | 2.68 | cMix (cld, rsd) |
| 2021/12/27 | TBD | TBD | TBD | 0.27* | 1.96* | 10.62* | 2.76* | cMix (rsd) |
The persistently high precomp averages in early December is what prompted me to move node on Dec 22. From ProtoNet I knew sub-11s precomp was possible on my hardware and didn’t want to wait for another cMix incident. Migration was uneventful (about 1 hour of planned downtime) and I managed to avoid missing an era.
Now earnings are still unstable, albeit higher (which is expected due to my location). And now I’m back to “manual” HA.
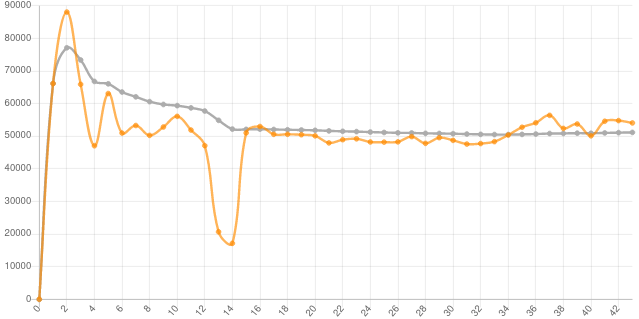
Week of Dec 27 isn’t done yet (Fri Dec 31, 2021), but so far both precomp and realtime failure rate have been good (apart from that mystery spike on Dec 26/27) and precomp average duration is 10.62 seconds which is better than I had in the cloud. Realtime failures and realtime duration are both great which is close or better to what I had in the cloud in past five-plus weeks, and very encouraging when compared with my mediocre ProtoNet performance on the same hardware with a 1% realtime and 3% precomp failure rates, and just 20,000 cMix rounds per week.
Now I’m close to best performers in my region (Oceania).
25,000 rounds per week was a nice round goal for this hardware configuration that I’ve finally achieved and intend to maintain while I attempt to launch the second node (“XXV2” in January 2022).
Status update on other items ¶
Due to the frequent incidents and five relocations in less than 50 days, all other plans have been progressing slowly. Here’s the current status, in order of perceived importance:
- Backup - 20% done; node migrations impacted this part the most, but at the same time I’ve gotten quite good at manual recovery and some essentials are in place. Lot to be done, of course.
- Performance monitoring - 70% done. I now “manually” monitor several indicators using custom scripts. This is largely meaningless (I could as well watch just the MainNet dashboard and Explorer, which I do), but with own scripts I get more detail about some low-level indicators I care about. This is closest to complete because I’ve had so many problems with cMix and stability and wrote those scripts to help me track them.
- Availability monitoring - 25% done. There’s a basic service (TCP port) monitor with notifications while “smart” monitoring is work in progress (scripts have been written for some key metrics and one key service). This isn’t so important because I check MainNet dashboard and Explorer several times a day.
Day 33 (Dec 22, 2021) ¶
After a mysterious network cock up in era 13, which I suspect wasn’t caused by me (I think it was something about the network, but I’ve never found any proof), I had to restart validation and miss some 0.7 days worth of earnings. The problem resulted in long series (15-20 rounds) of quick precomp failures followed by 2-3 good rounds. Really weird, I’d never seen that before.
After that it’s been two-three weeks of unremarkable but stable performance ranging 48-52K points per day. This node is still closed to nominators, but the next one won’t be. Whether it will manage to get elected is another question.
Day 12 (Nov 30, 2021) ¶
After days of part-time preparations, I’ve successfully adjusted my configuration so that it performs faster and better.
The changes cost me (and the nominators) two hours of downtime yesterday (Era 12) and around 30 minutes today (Era 13), but should pay back in days and weeks to come.
If this configuration indeed performs better I will revisit other items (monitoring, etc.) which have been delayed by attending to performance and stability difficulties during the first 12 eras.
Now that adjustments have been made I plan to just monitor everything for at least one week.
Day 11 (Nov 29, 2021) ¶
Some things have been going according to the plan, some haven’t. The bad stuff first.
ERROR condition on Node (Nov 22, 2021) ¶
I had one service disruption on Nov 22 due to a Node VM misconfiguration that was my fault. And of course I was away when it happened. Once I did discover it, I fixed it quickly.
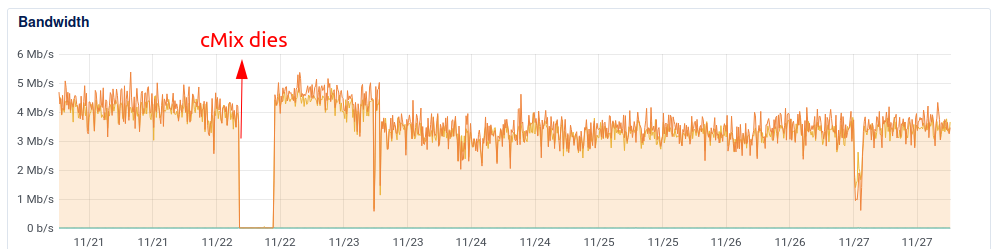
Actions taken:
- I more closely watch that particular metric (but automated monitoring still not in place)
- The problem happened in the era in which I raised my commission to the allowed maximum for nodes with Team Multiplier (13%). But, as Node downtime caused losses due to my fault, I did these things to partially make it up to the two nominators I had at the time:
- Revert commission from 13% to 10%
- Stop accepting new nominations, to allow them to remain on board at 10%
With that corrective action which was noticed only in the second era after the incident, the two nominators remained on board. In a week or two they should recover the missed earnings.
Chain remained online during that time, so some points were still earned (only less) during that cMix service disruption.
Service degradation on Node (Nov 26, 2021) ¶
The other problem happened due to external factors outside of my direct control, and I spotted it fairly quickly. But I didn’t do anything to cause it, and there was not much I could to to fix it either. cMix service simply started crashing every second or third round. After a while I tried to restart cMix service, then even reboot, then restart Gateway, too.

I’m not sure if any of those actions helped, but eventually precomp failures returned to normal. During a period that lasted approximately two hours the Node failed 30% of the rounds.
The impact on nominators was minimal (mainly due to small impact on points earned, but also thanks to their tiny share in my node compared to my own).
I suspect this problem is related to environment issues, as I had seen similar behavior before (ProtoNet). It only didn’t last as long. Who knows, maybe my rebooting and restarting delayed cMix recovery… I also wonder if I didn’t restart and reboot, maybe cMix would have eventually crashed and stayed offline like it once did on ProtoNet.
Temporary suspension of new nominations ¶
This is the good news. There’s a ton of good validators, so it’s not like people don’t have choices, but I want to explain why I’ve temporarily stopped accepting nominations:
- Mediocre performance: I’m not happy with my own service quality
- Responsibility: interests of validators and nominators are quite aligned, and there’s no promise of specific performance or mechanisms to deal with poor node performance other than what’s built into the system. Still, as I explained in other pages, it feels unethical to provide a service when I can’t recommend it to others
The good news is I’m making improvements and plan to resume in coming weeks.
Day 1 (Nov 18, 2021) ¶
Hours ago we started to cMix on MainNet. Current block height is 15,694, cMix round number 10870, and the time is Thu 18 Nov 2021 09:18:48 AM UTC.
Thankfully, I’ve had no issues at the open when validation begun.
Current status report after close to 11,000 rounds on MainNet:
- 454 rounds, 442 success
- 12 timed out (1.98%), 3 real-time time-outs (0.66%)
Day 0 v2 (Nov 17, 2021) ¶
As you probably know, we had a false start and had to click the undo button.
But I did not know that when I spotted my MainNet setup in the state of complete disarray, so I changed a bunch of things in the hour prior to MainNet v1 shutdown.
It took me two hours to update, undo changes and recheck everything. Tomorrow we’ll know if I have missed something.
Three hours until ~cMixing kicks off~ validator election process begins!
Day 0 v1 (Nov 16, 2021) ¶
The boxes (gateway & node) are ready to start validating.
I’m almost sure there will be problems with networking because I made some changes in the last hours of ProtoNet and they caused frequent timeouts in incoming connections. While I suspect and hope I saw a bug in permissioning behavior, if I see the same problem on MainNet, I’ll simply abandon that approach and revert to the old approach from BetaNet and ProtoNet.
ProtoNet ¶
November 2021 (1-15) ¶
We’re going to MainNet tomorrow, so although I’m going to keep the nodes up for another 12-24 hours, I’ll summarize this month’s run today:
As of now, Mon Nov 15 04:19:22 UTC 2021, these are my results for the weeks 1 and 2 of November, followed by the averages (unless indicated otherwise):
- Realtime timeout: 0.64 + 0.47 (0.55%)
- Precomp timeout: 3.08 + 2.32 (2.70%)
- Successful rounds: 20,708 + 20,153 (TOTAL: 41,861)
- Offline: 2.04 + 3.42 (2.7%)
Highlights and observations:
- Moving to the cloud - which I did only after 1/3rd into week 2 - improved realtime timeouts vs. October (0.83% to 0.55%). The cloud result is good even when compared to September (0.37%), because after 2/3rds of the week in the cloud, realtime failures for the week were just 0.47%. This seems just as good as September to me.
- Precomp timeouts were also significantly lower, and especially since I moved Node to the cloud (probably below 2%, if the node ran in the cloud throughout the week). In August, while running the node at home, I had only 0.16% failures, which now seems amazing and I can’t explain it (I didn’t change anything in my Node or environment between August and last week).
- Successful rounds: now this is a bad one. Extrapolated to the entire month I’d have 83K vs 91K last month, and almost the same as in the catastrophically bad September (83K). Why is this? It’s simple, the VM isn’t powerful enough.
- Time spent offline was 2.7%, a drop from October in which I had environmental issues, but still requires an explanation. This is related to moving from on-prem to the cloud (see Service Continuity notes) which caused 3.42% offline last wek. I also had a cMix service crash in-the-middle-of-the-night in the first week of November.
I want to add few more lines regarding the low number of successful rounds:
- Other nodes in East Asia (I’m not talking about the XX geo bin) are doing 110-120K/month, I am aware of that.
- There’s a geo-multiplier (initially 1.4x-ish for Eastern Asia), so I don’t need 130K rounds per month to make decent returns.
- It’s still not clear how successful rounds influence rewards. I know the theory (20 pts/round), but we don’t know what that will mean on MainNet. On ProtoNet, after node switch-over to the cloud in the era 742, I saw no obvious impact on points or rewards.
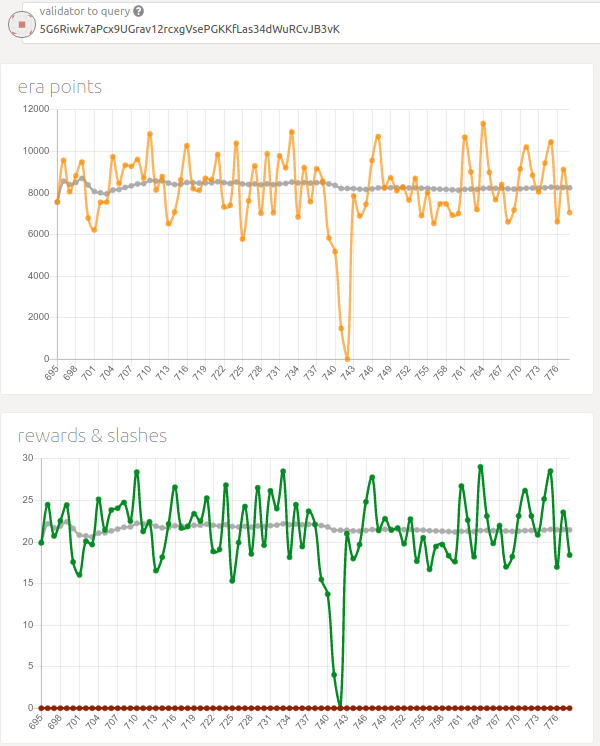
- Long story short: it isn’t clear if 83K successful rounds per month is a problem that needs solving.
I plan to revisit the performance in my next XX Network update (early December 2021).
October 2021 ¶
- Realtime timeout: 0.83%
- Precomp timeout: 3.07%
- Successful rounds: 91,262
- Offline: 3.79%
This month my node successfully participated in a lot more rounds than in September. I suspect the update from late September decreased the number of cMix crashes which means the node spent much less time recovering from fatal errors (crashes). It still crashed a lot, though.
The other thing is I spent more time offline compared to September:
- In one instance cMix was unable to recover from a crash, which pushed the node out from active validators and caused some downtime.
- In another instance, a brief power outage was handled without issues but chain on Node got confused and didn’t update which made cMix unable to work. Interestingly, chain service on gateway node located next to it was not impacted and remained up-to-date. I couldn’t find similar Substrate issues and the amount of debugging required to reproduce this is just not feasible, so I just let it go.
I don’t rely on online uptime checking service, but these failures reminded me that I should write custom service checkers for chain, cMix and gateway services.
September 2021 ¶
- Realtime timeout: 1.06%
- Precomp timeout: 3.17%
- Successful rounds: 82,509
- Offline: 0.77%
September was quite a disappointing month as far as my XX Network statistics are concerned.
The last cMix update in August 2021 was the main reason because it introduced new bugs and made existing bugs worse - I’m talking about the one that causes cMix process to crash and make the node effectively spend more than 5% of its time recovering from crashes.
The update from late September (v3.1.0) improved things a lot (in the second week of September my precomp timeouts were 15%), but the rest of the problems remain.
Yesterday they pushed anther update (v3.3.0) and because it happened over a weekend I spent some time looking at latest behavior of the node and - with the help of a XX Network team member - confirmed the long held suspicion that the comparatively higher (in East Asia) failures could be related to the fact that ISP routes traffic to scheduling server in Frankfurt via the United States, rather than Eurasian links. The bottom line is the 350ms latency to scheduling service is very bad.
And combined with other bugs - such as cMix crashes when one of five nodes in a round is unreachable - make the node need to check in with scheduling after each such round, which results in the next missed round, and the end result is more errors and fewer successful rounds.
I could make changes to my network to mitigate part of the problem, but MainNet is coming in 30 days and that’s when Scheduling is going away. So I’ll just let it be.
(Edit: later I learned scheduling and permissioning will not be removed on Day 1 of MainNet.)
Infrastructure (March 2022 status) ¶
| Item | XXV Node | XXV GW | XXV2 Node | XXV2 GW | Comment |
|---|---|---|---|---|---|
| Storage mon | OK | OK | OK | OK | mon = monitor |
| Simple cMix mon | OK | - | OK | - | simple port check |
| Simple Gtwy mon | - | TODO | - | TODO | TODO |
| Chain mon | TODO | TODO | TODO | TODO | TODO |
| Adv cMix/GW mon | TODO | TODO | TODO | TODO | TODO |
| DB backup | TODO | OK | TODO | OK | OK |
| Chain backup | OK | OK | OK | OK | |
| DB mon | TODO | TODO | TODO | TODO | TODO |
| Adv. logging | OK | OK | OK | OK | TODO: reports |
Team Multiplier and Phragmen make life of independent validators difficult, I don’t want to improve operations beyond minimum, so I’ve also stop updating this section.